91久久九九精品国产综合-91久久嫩草影院免费看-91久久青青草原线免费-91久久青青青国产免费-91久久人妻无码中文字幕-91久久人澡人人添人人爽-91久久婷婷国产一区-91久久香蕉国产熟女线看-91久久夜色精品国产-91久久夜色精品国产九色
<abbr id="qzaoq"></abbr>
<pre id="qzaoq"><fieldset id="qzaoq"><bdo id="qzaoq"></bdo></fieldset></pre>
<ul id="qzaoq"><blockquote id="qzaoq"></blockquote></ul>
<bdo id="qcu6u"></bdo>
<abbr id="qcu6u"></abbr>
<kbd id="qcu6u"></kbd>
上海也忘貿易有限公司
首頁
企業簡介
產品大全
聯系我們
企業信息
訪客留言
當前位置:
首頁
>
產品大全
>
上海港7月集裝箱吞吐量超430萬標準箱 創歷史同期新高
上海港7月集裝箱吞吐量超430萬標準箱 創歷史同期新高
如若轉載,請注明出處:http://www.liwangjd.cn/product/44.html
更新時間:2026-04-23 02:36:59
產品列表
PRODUCT
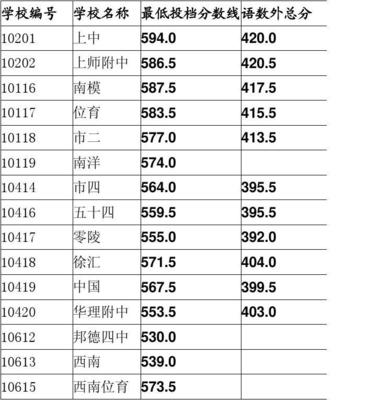
上海市徐匯區高中分數線
如何在進博會上奪得先機 看臺商臺企參與進博會的 花式玩法
聚焦綠色低碳 關注數字智能 第六屆進博會技術裝備展區前瞻
上海化妝品倉儲外包及配送物流
4350萬標準箱!上海港集裝箱吞吐量今年創歷史新高
上海興建亞太區最大的工業氣體生產基地(圖)
上海上海海港國際貿易中心寫字樓二手房房源,房價價格,小區怎么樣
上海貿易便利化又出大招 一鍵算出最少關稅 為進出口企業省大錢
大江東 專訪翁祖亮 推進高水平制度型開放
上海精品女裝外貿跟單做貨批發市場外貿服裝加盟代理外貿原單尾貨庫存服裝批發毛衣棉服衛衣帽衫 15966512157 上海精品女裝外貿跟單做貨批發市場外貿服裝加盟代理外貿原單尾貨庫存服裝批發毛衣棉服衛衣帽衫
主站蜘蛛池模板:
成人电影AV
|
操比超碰
|
91po福利姬
|
欧美成区
|
狠狠撸日日操
|
日本高清视频va
|
91孕妇被操大片
|
99视频热播
|
九一社一至36
|
91精品牛
|
天天肏视频
|
超碰日本成人
|
韩国福利影院二区
|
91原创视频在线
|
日本黄色网入口站
|
91次元
|
99爱操
|
超碰人妻在线
|
九一豆花网站
|
综合国产成人在线
|
超碰97操操操
|
av手机牛影院
|
熟妇的抽插
|
97午夜福利影院
|
性爱乱乱
|
超碰操逼逼网
|
91免费高清视频
|
俺来也导航
|
97久久草
|
欧美三级导航
|
日本韩国颜射
|
豆花视频久久
|
亚洲激情导航
|
欧美色另类
|
91内射在线
|
丁香亚洲午夜激情
|
欧美色色综合图片
|
中文字幕98
|
综合性交网
|
在线观看污视频
|
萌白酱在线
|
日韩素人无码
|
久久草草爱
|
四虎黄一级片
|
操碰porn
|
国产白一区二区三
|
人人97操
|
久热精品8
|
日韩成人动漫
|
激情综合BT
|
婷婷天天喊
|
日韩精品第三页
|
天天综合色图
|
人妖伪娘av天堂
|
91免费网站观看
|
国产区熟女
|
亚洲超碰在线
|
麻豆mv网站入口
|
黄色男女
|
日本日屄
|
日本网站www
|
日韩毛片网址
|
91制片在线观看
|
肏逼123
|
99色色伦
|
99视频热播
|
韩国无吗AV
|
91熟妇视频在线
|
午夜福利a毛片
|
岛国av影院
|
免费黄色链接
|
操人妻人妻
|
91福利官
|
日韩三极片
|
91呆哥人妻系列
|
日韩偶偶福利
|
国产tv六区
|
亚洲欧美都市激情
|
人妻欧美啪啪啪
|
豆花社区视频
|
婷婷国产视频
|
黑料网线路一二三
|
精品四区
|
青娱乐91精品
|
色色丁香五月婷婷
|
丁香五月成人
|
日本黄色高清视频
|
人人看人人摸97
|
少妇前吃后入
|
白丝巨乳被后入
|
日韩草逼
|
黄色地址五月天
|
大香蕉伊99
|
一本道成人在线
|
国产高清肏屄电影
|
国产TS在线免费
|
日本韩国毛片
|
91大家都在搜
|
国产白丝三区
|
日本美女视频
|
日韩肏屄肏屄
|
四虎精品福利导航
|
精品熟女91
|
91主播色
|
91n新网址
|
国产97超碰
|
色婷婷a
|
狼友免费
|
日本不卡AC
|
青青久久青青
|
91视频官网
|
51国产精品
|
久久瑟视频
|
AV黄色天堂网
|
av人人草
|
国产浮力影院限制
|
午夜无码人妻
|
99超碰大香蕉
|
探花AV网
|
超碰碰碰性爱
|
国产超碰99
|
青娱乐91论坛
|
欧美毛片网
|
亚洲情色国豆花
|
激情www
|
在线激情ab
|
91白虎免费观看
|
1024色中色
|
日韩qv
|
青娱乐无码AV
|
麻豆国产在线
|
国产女a
|
青青久久910
|
另类激情春色
|
午夜乱码
|
亚洲性夜
|
亚洲海角天堂
|
伊人婷婷麻豆
|
97色资源
|
豆花成人社区
|
老司机日日夜夜
|
国产精品第三页
|
欧美成人色图
|
美女九一视频
|
国产资源自拍
|
豆花官网免费进入
|
97色网络
|
91社区网站
|
成人97
|
国产91在线网站
|
国內精品久久
|
美女sese
|
日韩精品区
|
国产视频95
|
人人草超碰
|
久久影院福利社
|
伦理聚合一级
|
亚洲se97
|
狼人综合插
|
超碰www
|
欧美丝袜人妖
|
欧美一性
|
麻豆视频爱豆传媒
|
av黄网导航
|
黑人寄宿日本家庭
|
青青草原av
|
国产色A
|
俺去射官网
|
91自都在线
|
AV性爱社区
|
AV天堂电影院
|
六月天综合色色
|
国产青青在线
|
少妇午夜影院
|
wwww91色色
|
尤物天天干
|
蜜桃性爱
|
AV无码福利导航
|
激情欧美97
|
99色热
|
91网站国产
|
韩国三A91片
|
韩日激情av
|
91传媒在线免费
|
韩日123区
|
操人妻在线
|
在线免费九一网站
|
操碰视频免费
|
韩国三级大片
|
91www视频
|
99拍99视频
|
亚洲老司机www
|
97色伦影院
|
91AU视频
|
天天干天天干
|
少妇求操网站
|
av91福利
|
99精品在这里
|
浮力草草视频
|
WWW你懂的av
|
黄色片网站
|
狠狠鲁2026
|
天天操操操丝袜
|
91网站网址
|
91黄色片网站
|
久久草资源站
|
久热精品视频在线
|
午夜H片
|
狼友导航主页
|
欧美h喷
|
97超碰欧美
|
黄色精品资源网
|
韩日一区视频
|
殴美A∨
|
亚洲成人精品电影
|
91涩涩蜜桃
|
国产成人
|
97福利超碰
|
欧美操逼1区
|
青青草视频人人干
|
91蜜桃破解版
|
超碰在线人
|
成人看片网站
|
97人妻碰碰碰
|
草逼免费直接看
|
成人伊人影视
|
伊人久久网站
|
日韩AV大桥网站
|
亚洲另类文学
|
伊人大香蕉AV网
|
成人a高清免费版
|
国产成人精品久久
|
人人97操
|
免费性片
|
91社区在线播放
|
狼友TV
|
抖阴福利
|
97在线超碰丝袜
|
97在线视频总站
|
wwww无码
|
老司机精品网站
|
国产毛片AA
|
大香蕉五月丁香
|
日本中文字幕A片
|
青青国产在线观看
|
欧美日韩aa
|
蜜桃91视频
|
国产激情另类
|
精品国产区久久
|
五月天色导航
|
香蕉视频官网
|
探花精品系列
|
国产熟女一区
|
欧美另内A∨
|
操碰伊人
|
超碰在线97视4
|
99热草
|
91蜜桃网址
|
亚洲爱豆天堂玩
|
91偷拍在线
|
三级日韩中文字幕
|
大香蕉狠狠的
|
日韩国无码
|
91偷拍字幕视频
|
偷拍97av
|
av福利影院
|
美女自慰喷水网站
|
豆花午夜
|
日韩你懂得
|
91露胸
|
午夜寂寞影视院
|
国精品久久
|
av不卡电影
|
久久婷婷热艹黑丝
|
不卡海角91
|
欧亚一本视频
|
性交14p
|
人妻性交影院
|
香蕉伊人91
|
久草手机在线
|
www操C〇M
|
欧美人与兽A片
|
AV无限网站
|
日韩一页综合区
|
亚洲妞妞综合网
|
91c网站
|
99色国产
|
美女被草网站
|
www九九
|
亚洲精品露脸自拍
|
美女福利视频导航
|
自慰综合网
|
国产精品成人久久
|
午夜九二福利
|
欧美视屏
|
尤物天天干
|
东方四虎aV
|
午夜福利97
|
91白丝综合
|
午夜诱惑老司机
|
国产在线第一页
|
午夜少妇码无
|
97视频福利
|
日本男女肏屄视频
|
亚洲四房诱惑
|
伊人久久艹
|
日韩av资源网站
|
91超碰大香蕉
|
久久只这里有精品
|
久久国产媒体
|
天天干这里有精品
|
超碰99人人乐
|
伊人精品久久
|
韩日1区
|
亚洲日本性爱
|
人妖AV资源网
|
天堂AV导航
|
久久草福利导航
|
操操无码
|
成人电彯三级
|
九九性爱网
|
日韩47页
|
亚洲啪在线
|
日韩三级高清无码
|
日韩新片王网
|
日韩欧美性爱
|
中文字幕16p
|
91热爆TS伪娘
|
国产久久精品
|
日本不卡线
|
成人VA视频
|
97人人视频
|
Av性爱中文
|
麻豆黄色网
|
草莓视频导航
|
超碰美国
|
91综合在线观看
|
国产精品日韩无
|
91星空
|
久久尹人综合网
|
美女超碰在线
|
日韩视频1
|
东方四虎色av
|
福利网导航
|
91次元黄色pc
|
久久福利社
|
成人日韩免费
|
东京热色综合
|
国产亚洲一区3t
|
狼友福利群
|
九九九毛片在线
|
日韩av线路
|
无码AV电影
|
91人色网
|
豆花AV永久地址
|
成人瑟瑟网站
|
少妇导航福利
|
国产精品久久AV
|
激情福利导航
|
超碰人人肏
|
综合肏屄
|
豆花导航福利
|
人人操人人干网
|
人妖狼人另类
|
久久天堂影院
|
四虎色情
|
不卡性爱网
|
综合97超碰
|
在线国产超碰9
|
色色91下载网站
|
午夜草逼
|
99超碰久
|
变态另类人妖综
|
伪娘网站黄色
|
天天干高清
|
在线观看黄色电影
|
大香蕉午夜福利
|
91极品反差九色
|
91精品黑丝
|
久草夜福利
|
久久人阁
|
91大神免费网址
|
日韩A∨
|
丝袜香蕉论理
|
91怕怕
|
欧美日韩在线a
|
精品不卡视屏
|
A级香蕉视频
|
欧洲色视频
|
香蕉视频污视频
|
超碰97在线观
|
午夜寂寞福利
|
91夫妻交友
|
国产日韩欧美黄色
|
人人操人人肏
|
日韩午夜电影
|
97视屏91
|
韩国射无码
|
91试香蕉视频
|
亚洲天堂2025
|
91人体
|
日韩免费乱轮网站
|
黄色A级
|
国产激情内射
|
韩国电影色色
|
www狠狠干
|
www豆花51
|
加勒比操逼
|
美国性福福利导航
|
人妻自拍色图
|
久久成人免费
|
欧美性爱网址
|
俺去也com
|
日本AV网站
|
国产乱轮精品
|
日韩肏逼无码
|
尤物网站91
|
亚洲三级性爱
|
超碰碰人人妻
|
日日爱影院
|
超碰91大香蕉
|
AV剧场
|
91在线综合观看
|
91超碰操逼18
|
欧美日韩簧片
|
亚洲色图性爱
|
成人午夜大片
|
91原创社区
|
av性影
|
亚洲卡一
|
91视频东京热
|
探花对白清晰
|
色悠悠香蕉
|
欧美三级片官网
|
欧美激情另类
|
欧美激情rp
|
欧美操日本
|
综合五月久久
|
91福利影院
|
成人伊人电影
|
四虎午夜影院
|
www夜夜撸av
|
五月花社区电影
|
俺来也俺去也啪啪
|
福利社嫩草一二
|
91美女被啪啪啪
|
欧美性爱二区
|
影音先锋成人久
|
大香蕉自拍网
|
超碰九七AAA
|
东京热人人肏
|
91韩剧网
|
欧美另类性爱
|
99成人欧美
|
91传媒在线免费
|
久久潮久久添
|
黄色精品资源网
|
黄色毛片A片
|
成人在线不卡视频
|
AV天堂电影院
|
久草视频网
|
九一精品中文字幕
|
人人摸人人爱
|
伊人成人电影
|
日本人人插
|
欧美另类丝袜自拍
|
欧韩123区
|
91黄色仓库
|
欧美爽入
|
91蜜桃麻豆
|
精品自拍傳媒
|
最新91在线视频
|
91豆花吃瓜
|
日本视频a
|
另类极品AV
|
东京热AV资源网
|
色色视频
|
五月开心色色网
|
国产草逼观看
|
抖阴福利视频
|
涩涩爱com
|
欧美精品系列
|
日本歐美電影
|
91性爱视频
|
www03另类
|
超碰日本成人
|
av红绿首页
|
国产盗摄5区
|
浮力瑟瑟麻豆影院
|
五月婷婷操逼
|
午夜成人影片
|
制服丝袜狠狠干
|
91午夜伦理影院
|
伊人黄色视频
|
九九久久大香蕉
|
97超碰免费在线
|
成人板91
|
97视频国产在线
|
91爱爱王
|
五月天黄色影院
|
狼友TV在线观看
|
狠狠干网站
|
日本韩国电影无码
|
偷拍99超碰
|
午夜福利色片
|
欧美成人免费专区
|
AV网站全部
|
超碰AV导航
|
亚洲91黑丝
|
91蜜桃在线播放
|
极品91视频
|
黑丝自慰喷水网站
|
日本激情网
|
韩国91大片
|
在线观AV
|
欧美激情导航
|
91后入jk
|
91人人爽
|
91视频免费的
|
中文字幕国产主播
|
福利社性交A片
|
国产馆绿帽
|
www美女AV
|
日韩欧美精品撸
|
深夜福利网
|
国产18页
|
成人看片
|
国产丝袜看片
|
91午夜影院
|
91热爆伪娘
|
午夜另类成人AV
|
久久网91
|
91视频第十页
|
欧美变态另类
|
A片福利
|
91五码
|
黑丝系列影音先锋
|
超碰在线黑人97
|
人碰人操
|
操逼视频A
|
无码理论影院
|
成人三级网址
|
欧美福利中出
|
日韩A级
|
欧美aa网页
|
色综合香蕉81
|
91福利所
|
豆花自拍社区
|
超碰东京人人
|
第一富利导航大全
|
亚洲女性黄页网站
|
污视频观看
|
豆花肏肏视频
|
内射无码一区日韩
|
久久草福利导航
|
成人的性生注
|
国产免费日逼视频
|
人人操热超碰
|
亚洲微拍福利
|
91福利在
|
www99肏
|
肏逼舞夜影院
|
玖玖男人资源站
|
亚洲福利香蕉导航
|
男人的天堂无码
|
91N网站在线观
|
91无码精品蜜桃
|
久久超碰碰
|
萌白酱白虎
|
a片石榴视频
|
91内设网站
|
人妻热产精品6
|
91在线深夜
|
91后入
|
97超碰碰在线
|
欧美福利精品导航
|
日韩高清无码破解
|
51AV导航
|
91传媒免费观看
|
亚洲av含羞草
|
国产自产91
|
红桃成人电影
|
成人午夜福利剧场
|
瑟瑟五月天婷婷
|
超碰男女
|
国产日逼网
|
97色团精华液
|
韩日无码射
|
性爱网日韩av
|
亚洲天堂精品视频
|
国产干逼的
|
AV国产做爱
|
色午夜影院啪啪
|
激情色色无码
|
国产区地址91
|
日韩老湿有码日韩
|
日本αV中文字幕
|
老司机午夜视频
|
国产乱轮久久
|
综合午夜网
|
美女足交网站
|
免费观看黄色电影
|
51黑料福利社
|
五月丁香成人网站
|
黄色成人18
|
91天作传媒
|
福利视频99
|
久草资源福利站
|
欧美日韩操逼片
|
亚洲成人网站网址
|
av资源共享
|
97視频
|
欧美淫色网
|
91传媒网站
|
东方四虎色av
|
国内久久
|
亚洲综合激情色网
|
91免费网
|
欧美性国产
|
色婷婷五月肏屄
|
丰满的大胸继坶3
|
久久草国产
|
91aiai
|
91青草娱乐
|
蜜臀91
|
黄色上床视频
|
熟女91网
|
另类av
|
A级无毛
|
欧美四级
|
91破解官网免费
|
九一特级毛片观看
|
激情超碰在线
|
欧美孕妇性爱一区
|
久久人妻人人操
|
白丝高潮玩哭
|
欧美国产综合日韩
|
91小视频在线看
|
91色伦理
|
AV操逼电影
|
www狼友
|
午夜精品福利白浆
|
肏屄视频网址
|
A片网站入口
|
日韩色日逼网
|
韩国操逼剧场
|
www欧洲精品
|
在线看91网站
|
91在线不卡
|
萌白酱在线
|
AV综合性爱
|
青青草99热
|
国产黄色成人在线
|
影音先锋三级网络
|
超碰性导航
|
国产操性
|
AV你懂得
|
韩国人妻Av
|
海角熟女
|
韩国牛夜av
|
成人深夜福利18
|
日韩无码导航
|
日日曹干
|
国产精成人品AV
|
在线免费毛片基地
|
av资源共享
|
亚洲色图13
|
91视频91自
|
91免费线上视频
|
九九这里是精品
|
精品十区
|
韩国伦理合集
|
欧美日韩另类另类
|
狼友深夜福利
|
91后入
|
老司机A片
|
激情综合网站
|
91vv免费视频
|
欧美韩日国产
|
日本第一页色网
|
久草成人手机在线
|
丁香五月花影院
|
91精品网
|
欧美久久成年网站
|
性爱网五月天
|
第一福利导航站
|
影音AV资源站
|
三级午夜伦理
|
成人dy亚洲
|
AV国产网址
|
伊人久久青草伊人
|
九九黄色视频
|
www性福导航
|
91视频国语免费
|
欧美日韩一级二级
|
国产天天干天天色
|
豆花影视无码黄色
|
综合色色综合
|
俺去也色洛洛
|
另类欧美综合
|
91蜜臀人妻中文
|
在线观看黄色电影
|
综合色网导航
|
91小网站免费
|
2026男人网站
|
韩国人妻Av
|
人人操B碰
|
91丝袜在线
|
91国产精选优质
|
久久色导航
|
超碰在线caop
|
AB色电影官网
|
ts人妖av
|
亚洲色图vu
|
午夜激情按摩
|
69欧美精品
|
老司机av综合网
|
欧美肏屄狂欢
|
在线播放成人网站
|
福利AV电影
|
国产日韩中文字幕
|
亚洲自拍色图
|
午夜伦理av
|
操碰熟妇
|
成人伊人电影
|
亚洲午夜居场
|
激情色色综合导航
|
人妻聚色窝
|
成人一级片
|
超碰96
|
高清无码网站导航
|
激情伊人
|
日本AV在线直播
|
国产av发布页
|
国产美女自拍视频
|
另类AV首页
|
天天天肏
|
性爱视频一区二区
|
黄色A片网
|
成人久久视频
|
欧美色图18p
|
美女的bb
|
91白丝在线看
|
玖草资源站
|
97一级影院
|
日韩肏屄一线天
|
欧美另类视频
|
性爱网日韩av
|
91碰在线观看
|
日本黄页免费
|
国产精品蜜芽AV
|
国产精品日韩欧
|
97精频
|
东方四虎色av
|
91JK视频
|
国产精v色
|
91视频在线播
|
97玖玖超碰
|
操碰高清
|
欧美人妖在线
|
久久国产精品视频
|
超碰碰激情
|
91探花入口
|
尤物天天干
|
欧美亚性激情
|
超碰人碰
|
国产白丝自慰91
|
日韩色网址
|
美女福利导航
|
日本屄视频
|
性爱剧场
|
韩日无码全集
|
激情有码天堂
|
91破解版片
|
超碰1931夫妻
|
97在线视
|
91电影双飞
|
亚洲三级片另类
|
俺去也俺来也
|
AV伦理影院
|
午夜视频在线导航
|
伊人91大香蕉
|
美女A片视频
|
狼人伊人
|
91在线看看
|
欧美另类激情
|
韩国电影黑丝视频
|
三级片网站播放
|
午夜香蕉av影院
|
91后入极品jK
|
日韩A片大区
|
伊人白虎五月天
|
91在线网页
|
日韩福利社区
|
欧美setu
|
欧美性爱tv
|
在线观看超碰
|
91人人视频
|
91传媒综综合网
|
麻豆免费在线毛片
|
成人伊人丫视频
|
人妖A片区
|
日本伦理乱片
|
成人午夜剧场A片
|
青青草大香蕉福利
|
91大赛福利视频
|
九一黄色仓库
|
操碰69
|
成人精品免费网
|
草莓视频色色
|
国产91视频播放
|
jk啪啪内射
|
九一亚洲网站
|
日韩一本道综合
|
91人妻在线视频
|
91精品网站免费
|
久草大香蕉91
|
黄色电影小说网站
|
99乱伦
|
欧美久久综合伊人
|
91国模
|
99超碰人人爱
|
91国产人妖
|
91尤物白虎
|
超碰99人人乐
|
国产精品打炮自拍
|
亚洲色色污
|
豆花视频精品付费
|
日本免费在线WW
|
黄涩91大片
|
豆花影院天天吃瓜
|
欧亚色图
|
日韩精品网
|
豆花视频在线观看
|
伊人网在线视频
|
超碰夫妻啪啪啪
|
极品白丝在线观看
|
后入91
|
无码专区伦理三级
|
超碰碰人人妻
|
www九九
|
福利精品店
|
国产视频久久探花
|
午夜肏屄网
|
肏屄剧场
|
欧美人妖熟妇
|
91福利网站
|
丰满的大胸继母3
|
黄色仓库app
|
国产内射播放
|
肏逼123
|
av在线色色
|
色宅男宅女91
|
久久精品六
|
青娱乐91论坛
|
青青操国产
|
老司机制服丝袜
|
91网站不用下载
|
豆花成人在线
|
麻豆吴梦梦视频
|
日本不卡线在免费
|
久久香蕉精品产品
|
国产专区路线
|
国产禁品无遮挡
|
超碰超逼
|
三级在线
|
五月瑟瑟夜夜
|
国产夫妻3p网站
|
老司机AVAV
|
91伊人五月天
|
四虎色播
|
无码导航
|
91網站
|
日韩群p
|
www蜜臀
|
九九在线资源网站
|
狠狠干2025
|
91激情双飞
|
超碰97人人干
|
天天干视频毛片
|
福利导航网
|
天堂AV淫导航
|
青青草视频
|
伪娘网站黄色
|
人妖丝袜H
|
91校花宝儿在线
|
黄色短片合集
|
免费毛片网址
|
国产成人
|
午夜男人电影A片
|
91精品国产孕妇
|
www麻豆tv
|
色综合图区
|
91天美
|
青青草在线网
|
欧色图综合
|
97超碰资源总站
|
麻豆视频在线观看
|
www美女AV
|
91黄色电影院
|
91黑丝高跟精品
|
欧美A视频
|
国产精品掏空网
|
伊人AV电影
|
黄色AAA片电影
|
韩国女人操逼视频
|
国产三级在线网站
|
91超碰青青
|
91精品网
|
中文字幕A∨码
|
伊人久久在线
|
国内福利视频
|
午夜黄色伦理
|
亚洲黄色免费网址
|
婷婷亚洲情色
|
狼友福利视频
|
精品自拍传媒
|
99热拍久
|
97操碰视频
|
天天爽天天弄
|
豆花日韩社区成人
|
99爱操
|
激情av入口
|
午夜大片
|
浮力操操逼
|
美女人人肏
|
91国产香蕉
|
亚洲成人伦理
|
岛国黄色在线
|
午夜成人
|
欧美AV性
|
91在线免费
|
91色软件
|
国产男女操逼视频
|
老湿机福利69
|
福利在线92
|
老司机黄色影院
|
91看片下载
|
伊人网av
|
精品人妻久久观看
|
日韩无毛
|
俺去射啦
|
在线观看污网站
|
韩国人妻Av
|
欧美色图p
|
不卡综合21
|
操逼视频软件
|
日本电影a级久久
|
日本成人A网
|
欧美精品传媒
|
日韩一本道
|
大香蕉资源网
|
成人a级网
|
青娱乐首页
|
久草女同精品
|
婷婷色情网
|
91大神内射
|
91黑丝白丝
|
在线观看超碰
|
日韩A片做爱网站
|
午夜免费网站
|
福利姬极品导航
|
激情五月天色色
|
青青91视频
|
福利社视频
|
性爱AV午夜
|
免费看黃色网
|
亚洲色天堂在线
|
探花成人AV
|
欧美性爱bb
|
日韩αV
|
午夜91视频
|
狠狠色97欧美
|
韩国免费aa
|
超碰91伊人
|
91黑丝视频网站
|
91私拍视频
|
日韩成人综合AⅤ
|
午夜精品剧场
|
久久四虎一二三
|
伊人狠狠干
|
人妖另类
|
日韩色网络
|
久久人妻人人操
|
五月天婷婷伊人
|
麻豆h片
|
五月花老湿机
|
91蜜拍
|
福利社色导航
|
亚洲五码蜜桃
|
日韩欧美大片
|
国产传媒91播放
|
欧美h版在线
|
www久久人妻
|
久草加勒比
|
天美传媒A片
|
肏屄的av天堂
|
18禁老司机福利
|
av18导航站
|
精品第十三页
|
91自摸
|
欧美在线免费观看
|
91精品国自产
|
人人乐人人妻
|
91次元黄人版
|
日韩vt中文
|
岛国黄色免费在线
|
亚洲a级
|
TS在线
|
亚州三级在线网站
|
在线成人网址
|
老熟女重口HD
|
久久草在线
|
爱豆传媒A片
|
www高清日韩
|
久久国产精品视频
|
操逼王123
|
老师机午夜性爱
|
深夜影院
|
国产精品精品久久
|
传媒精品国产9
|
天堂资源网站
|
国产精品入口果冻
|
色综合123
|
成人日韩av网站
|
尤物熟妇TV
|
91蜜桃破
|
成人三级黄色网
|
香蕉福利导航
|
超碰青草
|
欧美激情28p
|
TS人妖自慰
|
美女91知视频
|
久久草六月
|
日韩3级片网站
|
wwww污
|
国产片91
|
91干逼欧美
|
美女超碰碰
|
三级片网站播放
|
成人天堂噜噜
|
超碰午夜剧场
|
九一一区二区
|
国产情侣一区
|
国内自拍论理
|
久草97超碰在线
|
91可爱足交
|
青青草福利社
|
欧美熟妇bbw
|
99热精品9
|
韩日1区
|
www大男人影院
|
av激情
|
人妖网站上
|
人妻福利老司机
|
韩国美女AV导航
|
91交配
|
欧美精品浮力影院
|
国产精品v
|
91大香蕉探花
|
日韩AV激情
|
午夜色先锋
|
久久伊人艹艹
|
97在线观看视频
|
欧美啪啪91
|
91n免费处女在
|
国产中出在线观看
|
超碰97人妻人人
|
欧美三级片官网
|
91福礼专区
|
亚洲乱乱少妇后入
|
亚洲天堂精品在线
|
www干逼com
|
超碰日熟在线
|
蜜臀gv蜜芽
|
精品久久88
|
男人影院AV
|
91超碰图片
|
日本高清色www
|
成人又大又黄免费
|
欧美午夜激情影院
|
成人在线不卡
|
大香蕉伊人现现
|
青青热久
|
午夜激情网站
|
在线观看黄色电影
|
欧美性戟
|
成人小电影91
|
成人性交
|
国语对白在线播放
|
日韩黄色AV网站
|
少妇人妻影院
|
高清乱码毛片入口
|
日韩AV一区
|
成人网免费在线
|
在线91国产视频
|
日本a√在线观看
|
欧美黑人大吊
|
精品91网
|
午夜av综合
|
九九色色七七香蕉
|
91超碰人人在线
|
午夜视频在线导航
|
黄色网页大全
|
大香蕉伊99
|
AⅤ网站
|
AV福利午夜导航
|
国产女a
|
草比视频官网
|
巨乳老师被艹
|
国产精品日韩
|
久草香蕉福利
|
美女免费抠逼
|
欧美日韩国产91
|
浮力影院AV
|
欧美大胆a
|
操逼四91
|
肏屄剧场
|
熟女91网
|
香蕉在线观看视频
|
变态少妇网站
|
韩国免费福利A片
|
超碰成人网
|
福利二区
|
午夜精品导航
|
97涩涩资源总站
|
美女含羞草
|
一区二区免费日本
|
欧美性爱二区
|
福利社在线视频
|
97人人舔
|
日本岛国片
|
国产精品入口果冻
|
亚洲人成小说网
|
91九色海角涩涩
|
www狼友
|
欧美成人精品18
|
91激情
|
白洁高义系列
|
国内AV影院
|
老司机黄色网
|
ts男娘激情
|
成人AV在线资源
|
含羞草AV影院
|
午夜诱惑网站
|
欧美激情rp
|
豆花直播91
|
另类综合网
|
日本激情视频
|
91黄色片网站
|
黄色网网址网页版
|
欧美性免一区
|
日本淫乱人妻
|
国产不卡一区
|
亚洲老湿机
|
五月超碰在线婷婷
|
欧美第86页
|
青青草五月份天
|
91免费视频网站
|
91美女诱惑
|
日本操逼福利在线
|
黑丝制服影院
|
日韩涩涩入口
|
久草熟女
|
69欧美人妖
|
人人操人人色网
|
三级片导航
|
五月花综合入口
|
老司机香蕉久久
|
日韩欧美大片
|
岛国精品资源网站
|
无码av影院入口
|
岛国四级片
|
超碰ab
|
色先锋AV导航
|
91海角视频
|
九九国模色图
|
91TS人妖另类
|
婷婷五月天第五页
|
三级片av在线
|
一本道福利社
|
97激情网站
|
肏屄麻豆
|
超碰人人按
|
91豆花打开
|
天堂激情
|
国产干逼的
|
久久午夜论理片
|
日本视频网页
|
婷婷无码下载
|
99热超碰在线
|
欧美色网网址
|
超碰大香蕉
|
中日韩日日
|
黄色福利社毛茸茸
|
91色禁
|
91海角刮伦
|
老司机综合网
|
豆花在线免费
|
极品丝袜白浆
|
国产精品香蕉国产
|
三级国产在线观看
|
岛国片在线播放
|
国产探花第一页
|
久久资源网站无码
|
老湿机导航
|
97色色资源总站
|
免费一二三区
|
91变态软件
|
久草人妻福利
|
激情网站
|
青青操在线
|
黑料老湿机
|
免费三级欧韩
|
内射美女九色91
|
深夜狼友
|
丁香六月操
|
韩国无码精品
|
91精品导航
|
欧美激情28p
|
91在线视频福利
|
国产一二三高清无
|
成人午夜性剧场
|
欧美h网
|
午夜福利传媒影视
|
天天射综合
|
海角社区尤物
|
麻豆视频在线播放
|
午夜影院1秒
|
天天干天天操B
|
91shufu
|
www久久肏
|
欧美十日韩十成人
|
91夜色成人链接
|
五月花AV电影网
|
日本色情免费影院
|
97午夜福利影院
|
后入jk
|
国产精品素人
|
久操资源福利在线
|
亚洲国产迷奸Aⅴ
|
AV一区二区AV
|
婷婷碰碰
|
91超碰人人艹
|
色友一区二区三区
|
亚洲人成小说网站
|
九九99福利视频
|
伊人久久国产
|
91社国产精品
|
黄色网业网址
|
国伦精伦品
|
成人黄色AⅤ网站
|
97乱伦
|
91爱爱爱
|
国产熟女露脸
|
国产av豆花
|
韩国A级无码片
|
超碰在线免费主播
|
免费看片成人91
|
91综合在线视频
|
午夜福利激情网
|
人人操人人奸
|
女人的天堂网
|
福利姬在线导航
|
AV大香蕉
|
日韩人妻视频导航
|
AV午夜资源
|
国产精品探花少妇
|
美国三级毛片
|
午夜福利三级导航
|
日本A级电影网站
|
91偷拍字幕视频
|
国产推油在线观看
|
97瑟瑟影音先锋
|
国产片91
|
午夜神马福利51
|
国产精品扒开
|
欧美日韩中文字幕
|
欧美Aⅴ在线
|
51麻豆传媒
|
久草精品资源站
|
五月丁香影院
|
国产豆花AV区
|
超碰新地址
|
欧美大色
|
久草性生活片
|
美国一级毛卡
|
成人a高清免费版
|
成人久久视频
|
久久精品国产视频
|
人妖黄色网
|
色色综合总站
|
91视频露脸
|
精品二区欧洲
|
传媒精品国产9
|
女同性恋视频
|
日本特黄视频
|
www尤物
|
久久国产网站
|
日韩中文字
|
午夜寂寞福利
|
51AVTV导航
|
日韩淫色网
|
另类婷婷
|
香蕉网站在线
|
福利导航老司机
|
日韩一级免费视频
|
91在线观看
|
久草久草视频视频
|
五月天精品导航
|
韩国AA毛片
|
韩国午夜无码av
|
超碰91黑料
|
白丝唐伯虎
|
免费看黃色网
|
丁香影院
|
国产AV产
|
男人的天堂网页版
|
激情小色网
|
51社区精品视频
|
另类激情网站
|
91久久海角
|
女人毛片黄色
|
天天干干
|
日韩区二区
|
国产精品第十页
|
成人视频在线导航
|
人人操骚
|
婷婷色色五月天
|
91香蕉综合操网
|
黄色快播大香蕉
|
豆花传媒网官网
|
久久婷婷五月天
|
精品国产一二三
|
超碰人妻人人上
|
国产性爱在线
|
91黄色下载
|
97人妻人人操
|
福利二区
|
极品影视国产精品
|
黑丝喷水
|
欧美AⅤ在线观看
|
www麻豆传
|
午夜桃色18
|
东京热无毛片
|
91副利社
|
成人精品视频
|
AV国产网址
|
成人免费淫秽视频
|
国产色图专区
|
欧美一级黄色A片
|
国产精品电影
|
亚洲情色11
|
第一福利所AV
|
老湿机福利看片
|
97资源福利在线
|
蜜桃97干
|
91熊猫
|
少妇日皮
|
日本女人自淫
|
日韩欧美群P
|
福利社在线观看
|
后入91
|
日韩肏屄网站
|
久久五月资源网
|
久草超碰在线
|
超碰碰人妻無碼
|
日韩国产传媒
|
日韩区二区
|
微拍亚洲色
|
久久蜜芽影视
|
日韩av片网站
|
91入口黑丝
|
先锋资源成人av
|
男人资源
|
成人午夜剧场av
|
超碰碰91
|
91操操操操操操
|
午夜福利小视频
|
69成人免费视频
|
国产鬼片a片
|
91久久久
|
超碰在线女人
|
超碰av天堂
|
高清在线观看av
|
在线AⅤ
|
亚洲最色网站
|
日韩avcom
|
99热网站
|
午夜福利96
|
91唐伯虎
|
欧美色日本
|
国产成人AV
|
豆花成人精品
|
99视频国产在线
|
自拍优物193
|
91碰在线观看
|
护士AV采精AV
|
WWW浮力COM
|
岛国片免费
|
韩国av啪啪
|
伊人阁婷婷
|
久草香蕉福利
|
黄色福利导航
|
91视频东京热
|
人妖A片
|
日韩快播区
|
91破解网官网
|
久久精品这里18
|
操逼网站97
|
久久一期二期中文
|
91性条小网站
|
白丝尤物被后入
|
传媒AV影视
|
俺来也色精工厂
|
91fuli在线
|
91公司制作传媒
|
成人在线观看网址
|
成人小视频APP
|
91欧美色图久草
|
日韩超碰在线
|
肏屄视频网址
|
超碰在线va
|
天天操精品
|
丝袜熟女一区在线
|
狼友导航主页
|
豆花视频91在
|
另类情趣福利社
|
肏屄剧场
|
国产欧美伊人
|
爱豆传媒映视AV
|
日韩一级免费
|
91视频观看入口
|
91精品牛
|
激情伊人22
|
欧美A片色图图片
|
香蕉导航
|
操欧美逼
|
另类A片
|
国产少妇高潮视频
|
91白丝国产
|
天堂网东京热
|
国产情侣av
|
成人在哪看片
|
日韩欧美中文自拍
|
99资源人人草
|
午夜av理论
|
国内久久
|
精品aa福利
|
操欧美B
|
97亚洲资源总站
|
91探花在线播放
|
人妻在线亚洲精品
|
青娱乐网亚洲av
|
欧洲亚洲日本
|
国产免费美女大片
|
亚洲乱乱少妇后入
|
午夜av电影
|
91资源在线视频
|
欧美专区
|
狠狠谢影院
|
深夜福利网
|
AV日韩
|
久久伊人国产精品
|
91成品视频
|
欧美人妖网站
|
91快手网此
|
日韩avcom
|
91视频99视频
|
操人妻av
|
综合淫网
|
另类影音
|
AV免费精东
|
午夜无码影院
|
www日本
|
91伊人叉
|
中文字幕狠狠干
|
福利社区爱爱
|
欧美A片在线视频
|
午夜男人av影院
|
99精品66
|
成人视屏在线
|
亚洲AV炮图
|
超碰综合在线
|
AA欧美性爱
|
www性性
|
国产成人综合久久
|
91超碰资源总站
|
91经典免费视频
|
97人人爽
|
人妖资源网站
|
99草草网
|
国产91美女视频
|
国产同事高潮视频
|
av午夜影院
|
另类图亚洲
|
91视频完整版
|
日韩一级免费视频
|
欧美午夜群交
|
亚洲影院老司机
|
欧美无砖砖区
|
欧美黄色28
|
日韩精品一二三四
|
人人操人人奸
|
日本A级电影网站
|
99超碰人人草
|
色色午夜影院
|
美女网站91
|
人妖专区
|
国产精品第5页
|
欧美激情A图
|
狼友在线免费
|
欧美日韩国内
|
91红桃福利
|
麻豆AV影院
|
91草人网站
|
超碰91在线看
|
97人妻在线观看
|
99福利视频
|
宅男宅女AV在线
|
亚洲另类激动视频
|
日韩成人黄色免费
|
免费操性逼色
|
亚洲限制级AV
|
www91社
|
亚洲伊人网香蕉网
|
欧美色日
|
91ncom处女
|
九九视屏
|
97人人擦
|
欧美激情论坛
|
亚洲AV狼友网
|
天天干免费看
|
人人插人人操
|
免费成人毛片
|
都市激情另类
|
99桃色色首页
|
天天干干
|
亚洲精选中文字幕
|
91日韩区
|
欧美日韩色色
|
日本人妖色网站
|
囯产精品久久
|
91传媒熊猫视频
|
日韩一级免费观看
|
99精品66
|
尤物导航
|
香蕉福利导航
|
午夜无码久久
|
欧美性爱网
|
91夜色69
|
亚州日韩视频
|
日韩成人网站
|
亚洲最色网
|
国产美女
|
天堂男人av
|
成人黄色av影视
|
欧美日韩ab片
|
日韩肏屄一线天
|
大香蕉伊人毛
|
国产乱轮9
|
久艹视屏
|
国产av影院
|
91在線免費看片
|
大香蕉A91
|
欧美日韩vv
|
成人AV社区
|
91熟女精品91
|
精品伦理
|
日韩精品网
|
欧美青青草网
|
国产ts片网址
|
另类欧美综合
|
91无毛精品
|
91巨炮永久
|
女同视频在线观看
|
国內精品久久
|
九一福利视频
|
日韩理论在线
|
成人av福利院
|
先锋av影视导航
|
黄色在线观看网站
|
91国产微拍
|
无码爆乳久久
|
老湿机午夜
|
亚洲涩涩免费
|
AV老司机
|
国产精品素人
|
中文豆花AV
|
欧美专区一区
|
欧美色图91
|
日韩AV首
|
玖草在线
|
伊人在线欧洲
|
日本生活片
|
欧美色图另类
|
人妖社区午夜剧场
|
老湿机操
|
东方成人AV无码
|
操逼片不卡
|
久草性生活片
|
青青肏屄
|
久草福利视频蜜桃
|
日本在www电影
|
色色撸大妈
|
加勒比综合影院
|
国产插逼视频
|
91大神导航
|
狠狠久久乐
|
国产日韩久久影院
|
偷拍亚洲色图
|
豆花一区
|
免费看阿片
|
探花色色18
|
三级片精品在线
|
久草导航
|
草草视频亚洲
|
日韩二级色色视频
|
午夜羞羞成人
|
欧美日韩在线a
|
蜜桃超碰
|
超碰另类
|
麻豆区91
|
东京成人网
|
色色干新网
|
91微拍福利视频
|
国内自拍AV一区
|
导航美女福利
|
黄色免费视频网站
|
丝袜少妇足交
|
91人妻激情视频
|
久草女同精品
|
97cao操
|
福利导航
|
另类极品AV
|
超碰日日夜夜
|
亚州第一AZ
|
欧美色色图
|
神马午夜伊人
|